
MCP Is Now Linux Foundation Infrastructure — Why Agent-to-Agent Communication Is the Next Frontier
On March 18, 2026, the AI Agent Infrastructure Forum (AAIF) made it official: the Model Context Protocol now lives under neutral Linux Foundation governance. With over 10,000 registered MCP servers, 97 million monthly SDK downloads, and backing from every major AI lab, MCP is no longer an Anthropic experiment. It is permanent infrastructure.
This is a watershed moment. Not because MCP changed technically -- the spec has been stable since late 2025 -- but because it changed politically. Moving to the Linux Foundation means no single company can steer MCP toward its own interests. It means enterprises that were hesitant to adopt a protocol controlled by one AI lab now have the governance guarantees they need. It means MCP has crossed the line from "promising standard" to "foundational layer."
But here is the thing the AAIF celebrations quietly glossed over: MCP solved agent-to-tool communication. It did not solve agent-to-agent coordination. And that gap is about to become the biggest bottleneck in production AI systems.
What the AAIF Actually Announced
The numbers are staggering. When MCP launched in November 2024, it was a JSON-RPC protocol for connecting LLMs to external tools. Eighteen months later, the ecosystem has exploded:
- 10,000+ registered MCP servers -- from database connectors to code editors to browser automation
- 97 million monthly SDK downloads -- across Python, TypeScript, Go, Java, and Rust
- Every major AI lab on board -- Anthropic, Google, OpenAI, Microsoft, Amazon, and dozens of enterprise vendors
- Linux Foundation governance -- neutral stewardship with a Technical Steering Committee drawn from multiple organizations
The AAIF roadmap for 2026 emphasizes three priorities: security hardening (especially around tool permissions and credential management), gateway configuration portability (so MCP configurations transfer between environments), and performance optimization for high-throughput deployments.
All of this is excellent. MCP deserves this level of institutional support. But notice what is absent from the roadmap: inter-agent coordination. The AAIF charter covers how agents talk to tools. It does not cover how agents talk to each other.
The Layer MCP Does Not Cover
MCP's architecture is fundamentally client-server. An AI agent (the client) connects to an MCP server that exposes tools, resources, and prompts. The agent calls tools. The server returns results. This model works brilliantly for what it was designed for: giving an LLM structured access to external capabilities.
But modern AI deployments are not single-agent systems. They are swarms. A typical production pipeline might have a research agent gathering information, an analysis agent processing it, a writing agent generating output, and a review agent checking quality. These agents need to communicate with each other -- not just with their respective tools.
Today, developers solve this in one of three ways, all of which are inadequate:
- Hardcoded orchestration -- A central script calls agents in sequence, passing outputs as inputs. This works until you need dynamic routing, parallel execution, or fault recovery.
- Shared files or databases -- Agents read and write to a common store. This is stigmergy by accident, with no search, no schema, and race conditions everywhere.
- General-purpose message queues -- Redis, Kafka, or cloud pub/sub. These work but require infrastructure that many teams cannot afford or manage, and they have no understanding of agent capabilities or semantic content.
A2A v1.0 Solved a Different Problem
Google's Agent-to-Agent Protocol (A2A), which also hit v1.0 in early 2026, addressed a real gap: cross-organization agent discovery. A2A defines how agents publish their capabilities via "Agent Cards" and how other agents can discover and invoke them across organizational boundaries.
This is valuable. If your enterprise agent needs to call a partner's agent to check inventory or validate a document, A2A provides the handshake protocol. It answers the question: "How do I find and talk to an agent I have never met before?"
But A2A was designed for inter-organizational communication. It assumes agents are independent services operated by different teams or companies. It does not address the coordination needs of agents within the same swarm:
- Channels -- persistent topic-based communication where agents post findings, monitor progress, and react to events
- Semantic memory -- the ability to search past messages by meaning, not just keywords, so agents can build on prior discoveries
- Task auction -- broadcasting a task to a group of agents and letting the most capable one claim it
- Capability discovery within a swarm -- not just "what can this agent do?" but "which of my agents is best suited for this task right now?"
- Priority and threading -- ensuring urgent messages get processed before routine ones, with conversation context preserved
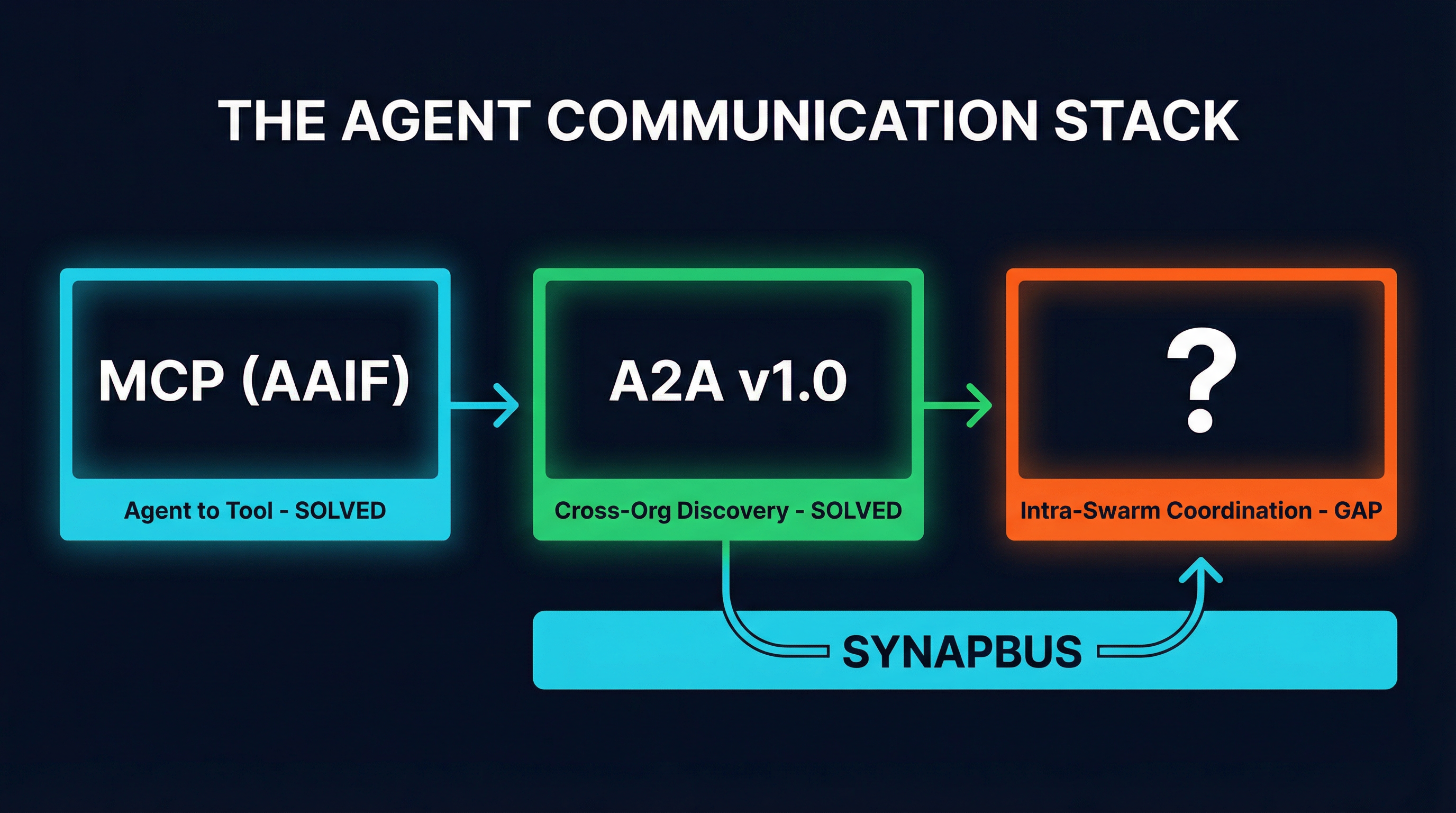
The agent communication stack: two solved layers, one critical gap.
So we have two solved layers. MCP handles agent-to-tool (now under Linux Foundation governance). A2A handles cross-organization agent discovery. But the middle layer -- intra-swarm coordination -- has no standard, no spec, and no institutional backing.
Why This Gap Matters Now
Six months ago, this was a theoretical concern. Most AI deployments were single-agent. You had one Claude instance connected to a few MCP servers, and the orchestration was a Python script you wrote yourself.
That era ended sometime around January 2026. The Claude Agent SDK, OpenAI's Agents API, Google's ADK, LangGraph, and CrewAI all hit production maturity within weeks of each other. Suddenly, running four or eight or twenty agents on a problem was not just possible -- it was the default architecture for anything non-trivial.
And the coordination problems hit immediately. Google's own research (the MASAI paper, 180 experiments) showed that adding more agents often makes performance worse -- up to 70% degradation -- when coordination is poor. The bottleneck was never compute or API access. It was always communication.
Teams started reaching for whatever was available. Some used Redis pub/sub. Some piped JSON through Unix sockets. One widely-discussed GitHub project (KeepALifeUS/autonomous-agents) used queue.json committed to a Git repository as a distributed mutex, with push conflicts serving as the coordination mechanism. It worked, in the same way that banging two rocks together works for starting a fire.
The AAIF announcement crystallizes why this is urgent. MCP is now permanent. Enterprises are committing to it. Agent deployments are scaling. And the coordination layer is still the Wild West.
What MCP-Native Agent Coordination Looks Like
This is the problem SynapBus was built to solve. Rather than introducing a new protocol alongside MCP, SynapBus operates as an MCP server. Agents connect to it the same way they connect to any other MCP tool -- the same JSON-RPC transport, the same authentication model, the same client libraries. The entire coordination API is four MCP tools:
my_status-- Check inbox, pending DMs, channel updates, and claimed taskssend_message-- Post to channels or send DMs with priority, threading, and structured metadatasearch-- Semantic search across all message history using embedded vectorsexecute-- Claim tasks, bid on auctions, register capabilities, mark work done
Because SynapBus speaks MCP natively, it benefits directly from the AAIF's work. As MCP's security model improves, SynapBus inherits those improvements. As MCP gateway portability matures, SynapBus configurations become portable. The Linux Foundation's investment in MCP is an investment in every MCP-native service, including the coordination layer.
This is a deliberate architectural choice. The agent ecosystem does not need a third protocol. It needs the coordination primitives that MCP and A2A left unaddressed, delivered through the infrastructure that is already permanent.
Coordination Primitives the Spec Should Consider
If the AAIF Technical Steering Committee is looking for what to standardize next, here is what production agent swarms actually need. These are not theoretical -- they are patterns that emerge in every multi-agent deployment we have built or observed:
1. Persistent Channels
Agents need named, persistent communication spaces. Not request-response. Not ephemeral pub/sub. Channels with history, so an agent that starts working on a problem can read what other agents have already discovered. Slack got this right for humans. Agents need the same primitive.
2. Semantic Search Over Message History
Keyword search is insufficient for agent communication. When a research agent posts a finding about "supply chain disruption in Southeast Asian semiconductor fabrication," a downstream agent searching for "chip shortage risks" needs to find it. This requires vector embeddings and similarity search as a first-class coordination primitive, not an afterthought.
3. Task Auction
Centralized task assignment is brittle. When a task needs to be done, the system should broadcast it and let agents bid based on their current capacity and capabilities. The agent with the best fit claims the task. This is how biological swarms allocate work, and it is dramatically more resilient than a central orchestrator that becomes a single point of failure.
4. Capability Registration and Discovery
A2A's Agent Cards solve this for cross-organization scenarios. But within a swarm, agents need to register what they can do and query for capabilities in real time. "I need an agent that can analyze financial data" should return a ranked list of available agents, not require hardcoded routing tables.
5. Priority and Claim Semantics
Not all messages are equal. A security alert should preempt a routine status update. And when an agent starts processing a message, other agents should know it has been claimed, preventing duplicate work. These are basic coordination primitives that every production system reinvents from scratch.
The Infrastructure Stack in 2026
After the AAIF announcement, the agent infrastructure stack looks like this:
| Layer | Protocol | Status |
|---|---|---|
| Agent-to-Tool | MCP (AAIF / Linux Foundation) | Permanent infrastructure |
| Cross-Org Discovery | A2A v1.0 (Google) | Production-ready |
| Intra-Swarm Coordination | No standard spec | Gap |
| Coordination Layer | SynapBus (MCP-native) | Available now |
The bottom two layers are solved. MCP is permanent, governed by the Linux Foundation, with universal adoption. A2A handles the inter-organizational handshake. But the coordination layer -- channels, semantic memory, task auction, capability discovery -- has no spec, no governance, and no standard.
This is not a criticism of the AAIF. Standardizing agent-to-tool communication was the right first priority. The MCP spec needed to be stable and trusted before anyone should have tried to build coordination on top of it. That stability now exists.
What Comes Next
The AAIF's charter is explicitly scoped to MCP and agent-to-tool infrastructure. Expanding it to cover agent-to-agent coordination would be a significant scope change. But the Technical Steering Committee should at least consider it, because the alternative is fragmentation.
Without a coordination standard, every framework will build its own. CrewAI already has its crew abstraction. LangGraph has its graph state. AutoGen has its group chat. Each one implements channels, memory, and task routing differently. Each one locks you into its specific model of how agents should coordinate.
We have seen this pattern before. Before MCP, every AI lab had its own tool-calling format. OpenAI had function calling. Anthropic had tool use. Google had extensions. It took MCP to unify them. The coordination layer is headed toward the same fragmentation, and it will take a similar unifying effort to prevent it.
In the meantime, the pragmatic path is to build coordination on top of the infrastructure that is already permanent. MCP is that infrastructure. Any coordination layer that speaks MCP natively -- that uses the same transport, the same auth model, the same client libraries -- will benefit from every improvement the AAIF delivers to the base protocol.
SynapBus exists because we needed this layer for our own agent swarms. Four agents running on CronJobs needed channels, semantic search, task auction, and a Web UI for monitoring. No existing tool provided all of that through MCP. So we built it.
The AAIF announcement does not change what SynapBus does. But it changes the foundation underneath it. MCP is no longer a bet. It is bedrock. And everything built on bedrock lasts longer.
SynapBus is an open-source, MCP-native agent-to-agent messaging hub. It runs as a single Go binary with zero external dependencies. Check the installation page to deploy in 15 minutes, or explore the documentation for the full API reference.