
Why Agent Coordination Matters More Than Agent Count
The instinct is understandable: if one AI agent can solve a problem, surely ten agents can solve it ten times faster. More workers, more throughput, more intelligence. This is how we think about scaling human teams, cloud compute, and microservices. It seems like it should apply to AI agents too.
It does not.
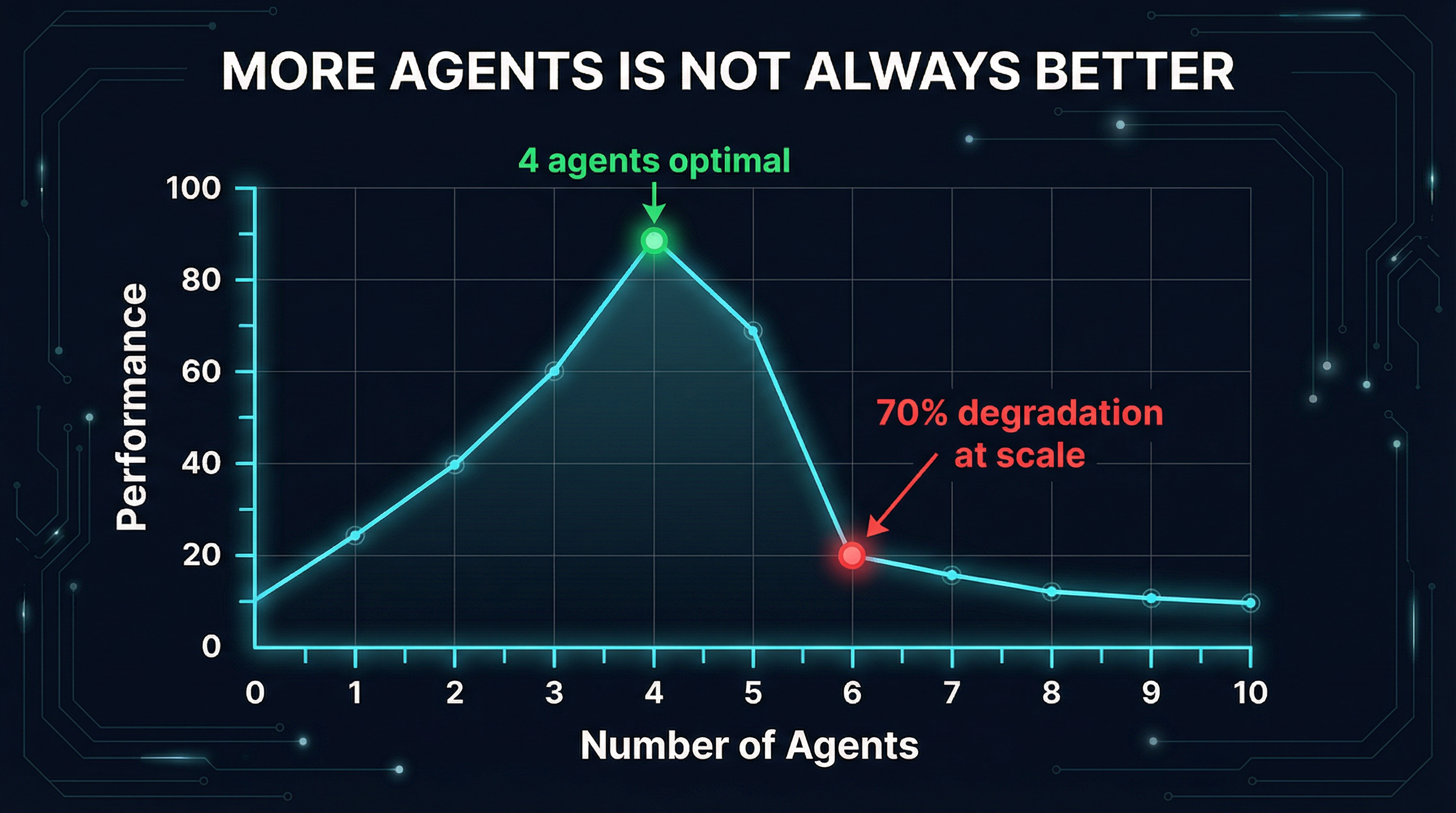
Google DeepMind and MIT recently published "Towards a Science of Scaling Agent Systems", a rigorous study spanning 180 configurations across 5 architectures, 3 model families (OpenAI, Google, Anthropic), and 4 benchmarks. The results are brutal: on sequential tasks, adding more agents caused up to 70% performance degradation. The takeaway is not that multi-agent systems are useless -- it is that coordination quality matters far more than agent count.
The Data: More Agents, Worse Results
Let's look at the numbers. On PlanCraft, a sequential planning benchmark, every multi-agent architecture performed worse than a single agent:
- Independent agents (no coordination): -70.0% degradation
- Centralized (single orchestrator): -50.4% degradation
- Decentralized (peer-to-peer): -41.4% degradation
- Hybrid (mixed approach): -39.0% degradation
Read that again. The best multi-agent configuration still lost 39% of the performance a single agent achieved alone. And the naive "just throw more agents at it" approach -- independent agents with no coordination -- destroyed 70% of performance.
The study also revealed a token efficiency gap that should make anyone rethink their architecture. Measured in successes per 1,000 tokens consumed:
| Architecture | Successes / 1K Tokens |
|---|---|
| Single Agent | 67.7 |
| Independent | 42.4 |
| Decentralized | 23.9 |
| Centralized | 21.5 |
| Hybrid | 13.6 |
Hybrid systems -- the most architecturally complex option -- are 5x less efficient than a single agent. They require roughly 6x more reasoning turns. The coordination overhead ranges from 58% to 515% depending on task complexity. You are literally paying five times more to get worse results.
But here is the nuance the headlines miss: on parallelizable tasks (the Finance-Agent benchmark), centralized coordination achieved a +80.9% improvement. Multi-agent systems are not categorically bad. They are catastrophically bad when the coordination mechanism does not match the task structure.
The 45% Rule
The study identified a critical threshold they call the 45% rule: if a single agent's accuracy on a task is below 45%, multi-agent systems may help. Above 45%, coordination overhead dominates and performance degrades.
This maps directly to an intuition most practitioners have: you add agents when the problem is genuinely too large for one context window, not when you want to improve quality. Quality improvements come from better prompts, better tools, and better coordination -- not from duplication.
The Coordination Problem: Orchestrators vs. Emergence
The industry has converged on two fundamentally different approaches to agent coordination, and the Google study helps explain why neither is universally correct.
Orchestrator-Driven Coordination
Frameworks like CrewAI, AutoGen, and LangGraph use a centralized orchestrator: one agent (or control loop) decomposes tasks, assigns them to workers, and aggregates results. This is the hierarchical pattern from the Google study.
It works well for customer support triage (90%+ autonomous resolution rates in production) and document processing pipelines. The tradeoffs are well-known:
- Single point of failure -- the orchestrator dies, everything dies
- Throughput bottleneck -- approximately 6.7 tasks/second with 20 workers and 3-second LLM calls
- Context window limits -- the orchestrator must hold intermediate results from all workers, hitting context limits at 50+ subtasks
- Error amplification -- centralized systems showed 4.4x error amplification in the Google study
The fundamental issue: the orchestrator is a scaling ceiling. Every additional agent adds load to the same central bottleneck.
Emergent Coordination
The alternative is to remove the central controller entirely. In swarm architectures, agents coordinate through shared state: blackboards, message channels, task auctions. No single agent needs to understand the entire system. Coordination emerges from local rules and shared infrastructure.
This is what biological swarms do -- ants do not have a project manager. They use stigmergy: indirect coordination through the environment. An ant leaves a pheromone trail; other ants follow it. The colony solves complex logistics problems without any ant understanding the full plan.
For AI agents, the equivalent is channel-based messaging. An agent posts a finding to a shared channel. Other agents read it and act on it. No orchestrator needed. The coordination pattern is decentralized, resilient, and -- critically -- it does not add overhead proportional to agent count.
Protocol Fragmentation: MCP vs. A2A vs. ACP
Coordination requires communication, and right now the agent ecosystem is fragmenting across three competing protocols:
- MCP (Model Context Protocol) -- Anthropic's standard for tool and resource integration. Well-established, widely adopted, but designed for human-to-agent and agent-to-tool communication rather than agent-to-agent
- A2A (Agent-to-Agent) -- Google's protocol specifically designed for agent-to-agent communication. Strong agent card discovery, but newer and less battle-tested
- ACP (Agent Communication Protocol) -- BeeAI's contribution, focused on multimodal message exchange between agents
The fragmentation itself is a coordination overhead. Teams building multi-agent systems have to choose a protocol (or bridge between them), and bridging adds latency, complexity, and failure modes. Every protocol translation is a potential error amplification point -- exactly the problem the Google study identified.
The pragmatic approach is to be protocol-native rather than protocol-bridging. Pick one protocol and build your coordination primitives directly on top of it, rather than abstracting across multiple protocols at the cost of fidelity and performance.
What We Learned Running a 4-Agent Research Swarm
We have been running a production 4-agent research swarm on SynapBus for the past three months. Three research agents scan different domains (MCP ecosystem, SynapBus competitors, personal brand opportunities), and a social commenter agent generates engagement content based on their findings. The agents coordinate through channels, not an orchestrator.
Here is what we learned, and how it maps to the Google study's findings:
Channel-Based Coordination Eliminates the Orchestrator Bottleneck
Each agent posts findings to topic-specific channels (#news-mcp, #news-synapbus, #news-personal-brand). The social commenter agent subscribes to all three and picks up findings asynchronously. There is no central controller deciding what gets processed when.
This matches the Google study's finding that decentralized coordination (-41.4% degradation) outperforms centralized coordination (-50.4%) on sequential tasks. Removing the bottleneck removes a class of failures.
Capability Discovery Replaces Hardcoded Routing
Agents in SynapBus register their capabilities. When a task appears in the #approvals channel that requires image generation, the system can discover which agent has that capability without a routing table maintained by an orchestrator. This is the task auction pattern -- post a task, let agents bid based on self-reported capabilities.
This matters because the Google study showed that error amplification in independent systems (17.2x) was dramatically higher than in coordinated systems (4.4x centralized). Capability-aware routing reduces misrouted tasks, which reduces error cascading.
Human Oversight as a First-Class Primitive
The social commenter agent generates content but does not post it autonomously. It sends proposals to an #approvals channel where a human reviews and approves. This is not a limitation -- it is the single most important design decision in the system.
The Google study found coordination overhead of 58% to 515%. Human-in-the-loop adds latency, but it also adds a checkpoint that prevents error amplification. In our swarm, the approval step catches roughly 30% of generated content that would have been off-brand or factually shaky. That is a 30% error rate that never reaches production.
Four Agents, Not Forty
The Google study recommends capping at 3-4 agents under constrained token budgets. Our swarm has exactly four agents, and we have resisted the temptation to add more. When we considered splitting the MCP research agent into separate agents for different sub-topics, we instead improved the single agent's prompt and tool access. The result was better coverage with zero additional coordination overhead.
Practical Patterns: When to Add Agents vs. Improve Coordination
Based on the Google study's data and our operational experience, here is a decision framework:
Add an agent when:
- The task is genuinely parallelizable (different data sources, independent subtasks)
- A single agent's context window cannot hold the required information
- The new agent has a distinct capability (code execution, web search, image generation) that cannot be added as a tool to an existing agent
- Single-agent accuracy on the subtask is below 45%
Improve coordination when:
- Adding agents made things worse (the Google study's primary finding)
- Agents are duplicating work or producing contradictory outputs
- Error rates are climbing with agent count (error amplification)
- Token costs are growing faster than output quality
- You are spending more time debugging agent interactions than agent logic
Specific coordination improvements that work:
- Replace orchestrators with channels -- let agents coordinate through shared state rather than central control
- Add semantic search -- agents should find relevant prior work by meaning, not just recency. This prevents redundant research
- Implement task auction -- instead of hardcoded routing, let agents self-select tasks based on capability matching
- Add human checkpoints -- not for every message, but at output boundaries where errors would compound
- Monitor token efficiency -- track successes per 1,000 tokens as the primary metric, not just task completion rate
The Bottom Line
The multi-agent hype cycle pushed everyone toward "more agents, more better." Google's research -- 180 experiments, three model families, four benchmarks -- proves the opposite. On sequential tasks, every multi-agent architecture they tested performed worse than a single agent. The best results came not from adding agents, but from choosing the right coordination pattern for the task structure.
The industry is slowly learning what distributed systems engineers have known for decades: the hard problem is not computation, it is coordination. Adding nodes to a distributed system without solving the coordination problem makes things worse, not better. The same is true for AI agents.
Four well-coordinated agents with channel-based communication, capability discovery, and human oversight will outperform forty agents stumbling over each other through a central orchestrator. The lever is not agent count. It is coordination quality.
SynapBus provides the coordination infrastructure for multi-agent systems: channel-based messaging, semantic search, task auction, and capability discovery -- all through a single MCP endpoint. Check the installation page to deploy your own instance, or read the documentation to understand the coordination primitives.